


Conjecture: A Roadmap for Cognitive Software and A Humanist Future of AI
On Carcinogenic Complexity, Software Senescence and Cognitive Provenance: Our roadmap for 2025 and beyond

At my dayjob, I run a startup called Conjecture. Recently, together with my cofounder Gabriel Alfour, I wrote a post describing the problems we see in the world of software, and how we intend to tackle these problems. I think it has enough interesting content for the audience of this blog to be worth republishing here. The original can be found here.
It is mandatory to start any essay on AI in the post-ChatGPT era with the disclaimer that AI brings huge potential, and great risks. Unfortunately, on the path we are currently on, we will not realize those benefits, but are far more likely to simply drown in terrible AI slop, undermine systemic cybersecurity and blow ourselves up.
We believe AI on its current path will continue to progress exponentially, to the point where it can automate, and summarily replace, all of humanity. We are unlikely to survive such a transition.
Powerful technology always comes with powerful risks, but this does not mean we have to wait idly for the other shoe to drop. Risks can be managed and prevented, while harnessing the benefits. We have done it with aviation, nuclear and other risky technologies, and we can do it again. But currently we are not on track to do so with AI.
What are we doing wrong with AI, and how can we do better? Given where we are currently with AI technology, what would it look like to actually build things safely, and usefully?
We think the answers are downstream of practical questions of how to build cognitive software well.
AI is often seen as a weird brain in a box you ask questions to and try desperately to cajole into doing what you ask of it. At Conjecture, we think about this differently. We want to take AI seriously as what it is, a software problem.
What would it mean to take AI seriously as software?
Part 1: Cognitive Software
The field of AI is weird. AIs are not like traditional software. They are more “grown” than they are “written”. It’s not like traditional software, where an engineer sits down and writes down line by line what an AI should do. Instead, you take a huge pile of data and “grow” a program on that data to solve your problem.
How these “grown” programs work internally is utterly obscure to our current methods of understanding, similar to how e.g. the human genome and its consequences for health are still extremely murky in practice. Even if we have the full genome of a patient sequenced, while we might be able to notice a few gene mutations that are well known to have certain effects, most of the genome and its functioning is completely unintelligible to us. We are in a similar situation with understanding neural network based AI systems.
This weird fact leads to much of the downstream strangeness of the AI field. We tolerate types and frequency of errors that would be unacceptable in any other context; and our methods for ensuring safety and compliance are pitiful in their efficacy compared to what would be needed given AI’s transformative potential.
AI, what is it good for?
The thing we want AI for, the thing ultimately we are using it to do, is to execute “cognitive programs”, to build Cognitive Software, so we claim.
When I say “cognitive programs” or “cognitive software”, what I intuitively mean is “the stuff you can get a human to do, but not (currently) a computer”, or “anything you could write down on a sheet of paper and hand to your intern and expect them to be able to do it reasonably well.” Things that we can’t (yet) formalize on a computer with traditional computer code.
This is what we want from AIs. “Sheets of paper with instructions handed to interns” are not currently executable by computers, but we would like them to be. These kinds of instructions are what most companies and human cognitive labor are built upon.
Our traditional methods of software development have not been up to the task of solving these problems, and so we have seen the emergence of methods of Cognitive Engineering, most famously neural networks, LLMs and Prompt Engineering. But the field is currently nascent, informal, and full of slop. The key to both an economically abundant and safe future is developing and wielding a mature field of Cognitive Engineering.
The way to develop the field of Cognitive Engineering is to think of AIs, and the workflows we make with them, not as magic brains that we talk to, or as inscrutable agents, but as software that needs to be developed, tested and maintained securely and effectively.
What can this view teach us about building better, safer and more effective AI systems?
A Tale of a Database
There is a really (morbidly) funny story, from a user on hackernews, who used to work at Oracle. For those unaware, Oracle is a legacy software company, mostly providing extremely expensive and baroque software and services to massive old companies. Oracle sells a database, the Oracle Database, and in the post, the user talks about how the codebase for this is one of the single worst codebases known to man.
It is millions of lines of poorly documented, confusing, horrible mess of code. No one knows how it all works, it’s all a messy disaster and it all relies on thousands of “flags” that all interact with each other in weird and undocumented ways. It’s hell!
And so the only way Oracle can do anything with this codebase is that every time they change a single line of code, they have to run literally millions of tests, which takes days on their cluster.
And every such change breaks thousands of tests, so you have to then go through each one, fiddle with all the flags, until eventually, at some point, you’ve found the right magic incantation of settings for your edge case, and can submit your code, which gets reviewed and merged sometime months later.
This is a terrible way to build software! Absolutely terrible! It’s not just extremely inefficient and costly, but there is also just no way to actually find and fix all possible bugs or vulnerabilities.
It’s simply impossible to design software that is safe and effective this way, it can’t be done, it’s too complex, no one understands the code well enough. I can guarantee you there are numerous fatal security flaws hidden in that codebase that just cannot ever practically be discovered or fixed, it’s just too complex! Complexity is the number 1 enemy of security.
This is not how we want to design real software for real world applications, especially mission critical or in high risk environments!
The Punchline Should Be Obvious
And the punchline to the Oracle story is: This is how we currently develop AI, but worse!
At least Oracle had a codebase, we don’t have a codebase at all, no matter how terrible! Our AI is a neural network, a huge blob of numbers, that we can’t look inside of or understand!
The way we currently build cognitive programs is to throw the largest pile of slop we can find into our GPUs, run inscrutable linear algebra over it, and then ask the resulting LLM to solve our problem. And then if it fails…what?? Try again? Ask more nicely? Feed it more slop?
And then maybe, if we’re really following “best practices”, we run a huge suite of “evals” on our model and squint at the numbers and see if they move in a good way or not. But these are not tests! At least at Oracle, they can write tests that test each little part of the code in isolation, or each specific edge case.
But we can’t do this with AI, because we don’t know how the internals work and how to test them properly. We can’t find every edgecase, or test every “subpart” of the neural network in isolation. And “fixing” one eval often breaks other ones, with no way to predict when or why. So we’re just guessing, and things can (and do) catastrophically break in ways our evals supposedly test for, constantly!
There is no process, no science, no systematic method to debug or understand why your prompt or AI didn’t work, or to find what edge cases would break it. It’s completely brute force, trial and error, no better, worse even, than Oracle’s magic flags!
This is a terrible way to make complex software! There is no way to make this reliable, safe and effective, even if we really really tried! (and most people are not even really trying very hard)
Part 2: AI Slop and Complexity Debt
We can argue about the fine details of how much value AI has or has not brought to various parts of the economy, but one thing it has undoubtedly brought us is unfathomable amounts of utter slop.
AI has not just brought slop to your parents’ facebook feed, but also to software engineering. Both through the direct writing of dubious code due to (ab)use of coding “assistants”, and more directly by the AIs themselves becoming critical components of the software systems. The use of AI has been dramatically increasing the complexity and attack surface of software.
Complexity is the enemy in all domains, not just in developing software. Take a more general domain: Responsibility. As the complexity of a system, software, bureaucracy or otherwise, grows, it becomes harder and harder to assign responsibility to anyone, or anything, involved. Everyone knows this effect from interacting with massive bureaucracies: they are inhumane, there is never anyone in charge that is actually responsible for solving the problem, and so problems don’t get solved and no one is punished for it.
Imagine if for example Facebook was using a handcrafted recommender algorithm, made of code, and someone decided to add a line of code along the lines of “if user is part of $ETHNIC_MINORITY, downgrade their popularity by 10%”. If this happened, it would be easy to prosecute, the line is clearly findable and visible to a court. And even better: We could find which person wrote that code, and every person in the line of command that resulted in that line of code being written, while exonerating anyone not involved. This is great, we can detect when a bad thing happened, find exactly who and what is responsible, and make the necessary adjustments.
But, of course, the Facebook recommender algorithm is not made of clean code, and is instead a massive deep learning blob. So now, whenever it turns out that an unfavored political group was getting deboosted, they can (and do) simply wail “it’s The Algorithm!! It’s not our fault! How could we be responsible for the organic and unpredictable effects of people interacting with The Algorithm??? Should poor innocent white collar software developers and managers go to jail for what The Algorithm did???”
The antidote to this is simplicity (or at least, well managed complexity). Complexity shields people and systems from accountability and makes the system resistant to being changed and fixed. The more complex a system, the less accountability, the less responsibility and the less humanity.
Conversely, the simpler a system is, the easier it is to make a reasonable effort, to prove good faith and exonerate oneself if something actually goes wrong. Simplicity sets up the incentives so that people are incentivized to not fuck it up, because they would be personally responsible.
As an IBM presentation from 1979 famously said: “A computer can never be held accountable. Therefore a computer must never make a management decision.” And yet, computers now manage all of our online social relationships and media. And thus, no one is being held accountable when things go wrong.

The Strange Decoupling and Software Senescence
Perhaps the strangest thing about AI is how much it has decoupled the capabilities of your system from your understanding of the system.
Understanding is the core to simplicity. The more you understand your system, the more you can understand its indirect effects and externalities, the safer (resilient to accidents) and secure (resilient to attackers) you can make it and the easier it is to predict how it will act outside of its normal range (generalisation).
The more you understand a system, the simpler it becomes. “Perfection is reached not when there is nothing left to add, but when there is nothing left to remove.” When you don’t understand something, it’s muddy, easy to delude yourself, super complex. As you understand it more, things become simple, sharp, clear.
The better you understand a system, the easier it becomes for other people to work with, the easier it becomes to transmit and teach and build upon, to integrate with other systems. As you understand the boundaries and limitations of your system, integration becomes natural.
The typical flow of science is something like: “Messing around with some small thing” -> “You gain more understanding, which also gives you more capabilities, and all the other nice things above” -> “You build big reliable projects using your new understanding”
Generally, given a certain amount of understanding, there’s only so much you can do. Capabilities are bottlenecked by understanding.
For instance, in traditional software, as you add more and more capabilities to your software, it becomes more and more complex and brittle, unless you understand and manage its complexity very well, until eventually it becomes so complex that adding more capabilities or fixing bugs becomes an impossibly daunting task, and you are stuck. Many legacy software companies find themselves in this unenviable position. Call this “Software Senescence.”
But this doesn’t just happen in software, it applies everywhere. If you push too far beyond your understanding, you quickly get signal from reality that you are screwing up, and things start to break.
In AI, things are very different. You can in fact get more capabilities without increasing your understanding, just by shoveling more data into the GPUs. There is nuance to this process, of course, but it’s important to understand how different and more brute force this is vs the careful management of complexity you have to do with traditional complex software. You can’t just slam ever more lines of code into a codebase to make it better (despite the best attempts of many large corporations).
The “scientific” process of AI looks more like: “mess around with huge things” -> “gain no new understanding” -> “gain new capabilities but none of the nice properties above” -> “build big dangerous things”
This is extremely perverse. All of our natural expectations of this process are reversed. We intuitively assume that as a system becomes more capable, it comes hand in hand with better understanding and all the nice properties that come with that. If I see someone has built a much faster, more maneuverable and capable airplane than I can build, I assume he understands airplanes better than I do. But here, AI subverts our expectations, and we not only don’t gain the understanding we expect, but lose ever more understanding as capabilities increase.
Algorithmic Carcinogenesis
If the natural lifecycle of software terminates in arrested senescence, an ungraceful but not worsening stasis, then the natural lifecycle of AI leads to a form of algorithmic cancer. And it has been eating us alive for a while now.
Algorithmic cancer is an uncontrolled and unconstrained tumorous growth that infects everything it touches and crowds out healthy tissues, just as AI slop is crowding out true humane creations, and how social media and recommender algorithms killed the diversity and creativity of the old web before.
It’s pretty viscerally intuitive that there is something gross about the proliferation of low effort, mediocre AI content. Just try using Google text or image search for any common topic, and you can immediately see what I mean.
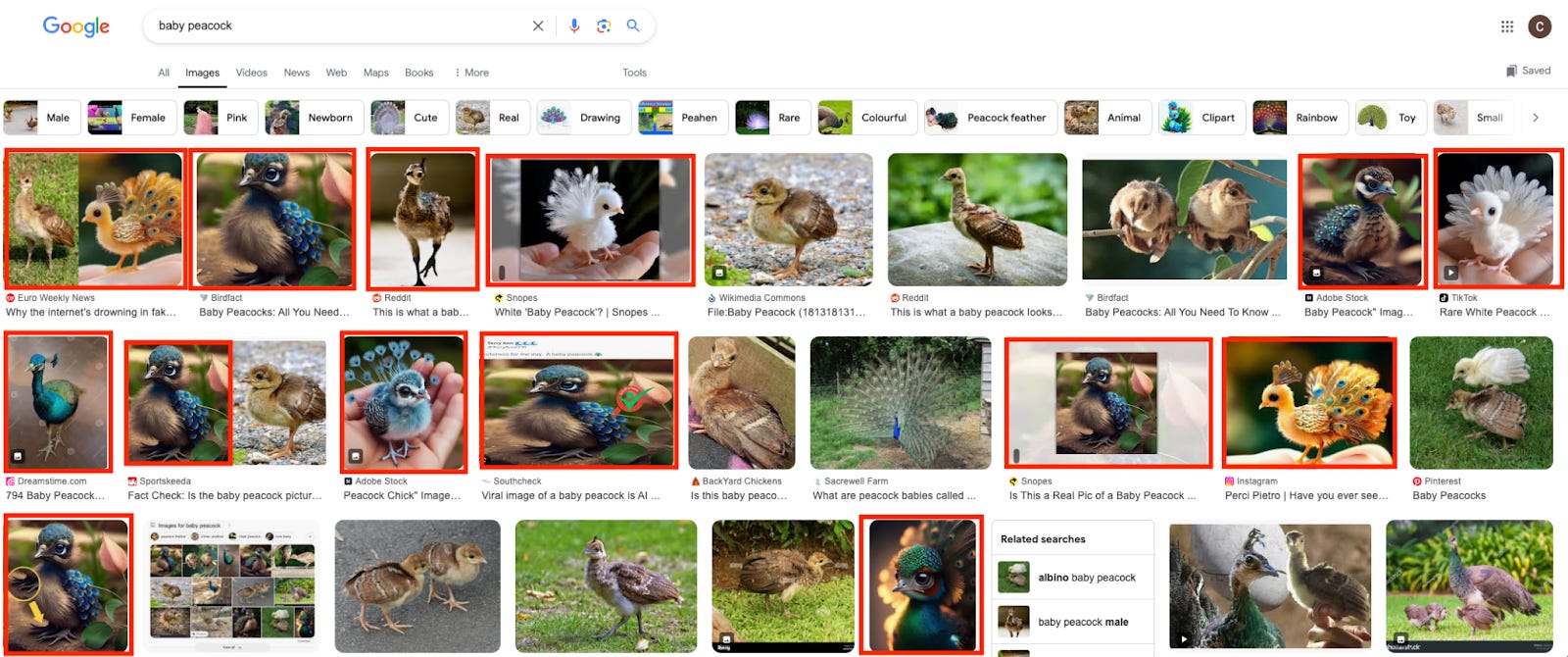
Pictured: A Google image search for “baby peacock.” Each image framed with a red box is a fake AI image. Baby peacocks do not have the extravagant tails associated with adult male peacocks. Knowing this makes these AI generated pictures particularly egregious and easy to recognise.
Having “more content” is not good, the same way having “more cells” is not good. A flood of the mediocre crowds out the actually good, what you are actually looking for, and rewards the lowest possible common denominator, anything that can trick or grab your attention for even a second.
The “demand” for cute baby peacocks with extravagant tails drowns out the pictures of actual baby peacocks, let alone the few unlucky human artists that put in the time and effort to accurately represent cute but realistic baby peacocks. Think of the work that goes into creating scientifically accurate artist’s impressions. Instead of putting in the hard, subtle labor of getting the visualization right, AI serves up the preconceived notions we already have and drowns out all other considerations we humans care about.
There has been a palpable sickness in the internet for quite a while, at least for the last 15 years or so. Gen AI slop is the most salient recent expression of it, but it is not where it started. Machine Learning’s first use wasn’t Gen AI. Lots of its earliest funding (at places such as Google, Facebook and YouTube) was in order to develop The Algorithm for social media.
Slop is not new to the AI era. Do you remember listicles? Buzzfeed? The transition from the wild, but human-built, west of Web 1.0 and early Web 2.0 to the homogenized, centralized, algorithmically curated walled gardens of social media? Machine learning was integral to the slop focused curation from day 1.
The mercy that Software Senescence grants us is that it at least provides something like a natural limit to the growth of cancerous software (even though large corporations spend a lot of money to counteract this effect and keep their virtual tumors alive and spreading). If your burgeoning tumor grows beyond your ability to manage, it at least doesn’t get much worse before utterly breaking down and (hopefully) being put out of its misery by either you or your competitors shortly thereafter.
And this again generalizes far beyond software. Historically, if you didn’t understand the chemicals you were working with, you would more often than not end up inhaling poisonous fumes or dying in an explosion, as was the fate of many alchemists and early chemists (remember: Every warning label on a chemical was, at some point, found out the hard way). There was a strong pressure to actually understand what you were dealing with, leading to all the fantastic benefits of modern science and civilization.
In the past, the feedback loop was short and direct. With AI, the effects are far more insidious: We all have a creeping feeling that our social life has deteriorated since the advent of social media, but it’s hard to pin down exactly what went wrong and when, precisely because the whole thing is so complex and inhuman.
Algorithmic cancer is dangerous because it doesn’t have a natural limit to its lifespan, its spread, or its virulence. If there is any further compromise on quality that can be made in exchange for more growth, cancer will take it. Every last bit of human soul snuffed out for maximal engagement. The cancer is in our media, our art, our software, our soul, it is everywhere, and it is spreading. And AI is its perfect vessel.
The enshittification and carcinogenesis of the internet has been supercharged by people building and deploying shitty, myopically designed and complex AI systems en masse. This is not the mere result of “The Incentives”, “Moloch” or “Technological Progress” at play. The people and companies involved have hired lobbyists to explicitly lobby governments and regulators to be allowed to keep doing this. This is not a natural phenomena, it is a deliberate pollution and toxicity induced carcinogenesis.
Cancerous tumors bring a lot of “growth” (by some metrics…), while making everything around them worse, and setting up the body for catastrophic, terminal failure. This is what is currently happening to our entire information ecosystem. Sounds like a great VC investment if you ask me!!
Neither New Nor Unsolvable
Is Conjecture somehow the first people to ever think about all this? Of course not, not by a long shot!
Healthy standards exist in many, if not most, fields. Other fields of engineering routinely predict and bound the effects of big things before they happen or are built: Bridges, airplanes, nuclear reactors… Anything that matters usually goes through a process of “stupid small thing -> science -> reliable big thing.”
We can quibble about how much science or safety is needed (FDA lol), but this is how good things happen in our civilization.
On the other hand, in machine learning, we just immediately deployed social media algorithms to billions of people without any constraint, oversight or science of what would happen. ChatGPT was deployed to 100 million people in less than 2 months. Anthropic just recently deployed full AI agents running on your computer. All of this is further, reckless carcinogenic pollution of our shared information ecosystem. All websites need to ramp up their security in response to these new systems, and we can now never be sure whether someone we are talking to online is really a human or not.
Sometimes people say things like “well so far AI hasn’t led to any large scale damage.” And I just couldn’t disagree more. Any time I am on social media now and see someone well articulately responding to my post, I can no longer be sure if it is a real person or not. AI generated images clog up search engines and crush artists, and social media recommender systems savage the mental health of the younger (and older) generations.
AIs have made a ludicrous number of people addicted to social media and waste their time. Instead of forming real human bonds, participating in civic and political life or building families, people made addicts by The Algorithm scream on social media. Instead of learning to make art with the wonderful help of the many resources on the internet, people are just resharing deepfakes.
All of this is explicitly the result of AI optimization. The few who do not fall prey to this do so despite AI, not thanks to it. This is the opposite of what technology should be!
The goal of technology is (or at least, should be…) human flourishing. We should be getting nice things, as people ascend Maslow’s hierarchy. But here, we are building technology specifically designed to alienate people and crush the human spirit: more complexity, less meaning (“it’s not our problem if people lose jobs or their communities are fractured”), appealing to base instincts, and all of this en masse and delivered directly to your smartphone, 24/7.
If we were to tally up the amount of effort, time and sanity lost to these effects…how high would that cost be? My estimate is it would be absolutely massive.
And who is paying for that? The people building and deploying these AI systems? No, it’s you and me. The river is polluted by the chemical companies and we are left drinking the toxic, carcinogenic water, while they lobby the government to not regulate them.
Remember SB-1047? It was a modest AI regulation bill that specifically asked for liability in cases where AI causes more than $500mln of damage (and no liability below that). And yet, tech companies viciously opposed, and ultimately killed, this bill. You can start to think about why that might be.
But it doesn’t have to be this way, it never had to be this way, and it wasn’t this way.
Historically, technology led to amazing things, and drastic improvements in human flourishing. The crises of fertility, housing, meaning, etc are fairly recent. This was not the norm for most technology for most of human history. Nobody expected this would be what technology would bring. Economists a hundred years ago were expecting a humanist post-scarcity by this point.
We have done great engineering in the physical world. Airplanes and nuclear reactors are astoundingly safe and provide much value to humanity, without demeaning and polluting our souls and societies.
So how do we embody this vision at Conjecture? The forefront of innovation in the 21st century has been software. Bits, not atoms. And what does the frontier of software look like? Javascript webapp framework slop as far as the eye can see.
Can we do better?
At Conjecture, we do Software, and history is also rife with examples of great software, principles and development practices that have stood the test of time and help us do the science to make our systems safe, secure and humane.
Famous examples include:
The Unix Philosophy. First laid out in 1978, these deep principles of modularity in software design can be translated to many different contexts and are often synonymous with what “good software” is.
The Relational Model and SQL. First proposed in 1969 (!), the Relational Model was a theoretical model, motivated by formal logic, to solve hard problems of how to store and retrieve complex structured data. This model turned out to be so good that basically all widely used, extremely performant databases even today, more than 50 years later, use this model. Even 50 years later, in an insanely competitive field of research, the RM dominates.
Type Systems and ML/Ocaml. Generally, there are 2 points at which you can catch a bug in your program: During running (asserts, validation), or after a program has run (debugging, looking at logs, pain). But there is a third, magical thing one can do, which is to catch bugs before running your program. Type Systems are one of the best and oldest methods for doing this, incorporating deep, powerful principles of formal Type Theory into programming to solve practical problems in a way that feels intuitive and deeply integrated into the language. It allows for fantastic UX for static analysis and formal verification. Programming languages that descend from this tradition, most notably ML (no relation to Machine Learning) and its descendants such as Ocaml, are some of the most amazingly well constructed and rigorous programming languages ever made. To this day, ML (which dates from 1973) is one of the very few languages completely specified and verified using formal semantics.
Good software engineering is Health, it is managing the health of information and software systems. And luckily, we have in fact learned a lot about how to build and manage the complexity of software over the decades. We should work hard to apply these lessons our senior engineers have learned via trial by fire to our new class of complex cognitive machines, or risk the next generation of software tumors crowding us out, and not just in the online realm.
What could it look like to develop principles and concepts as powerful as these for AI?
Part 3: A Better Future and How to Get There: A Roadmap
A better future is possible. We can learn to build AI as the complex software it is and harness the lessons from the history of software engineering. This is what we build at Conjecture.
We build the tooling to turn developing cognitive programs into a science, to treat it as a software engineering problem, rather than as negotiation with a weird little slop imp in a box.
As the world drowns in slop, our counter is to be extremely opinionated on all points to fight back against unsound defaults and norms. There are many places where things can go wrong, and our roadmap tackles each one, one by one.
Our roadmap can be roughly split into 5 phases, each building off of the previous, and becoming increasingly ambitious and experimental, taking us further and further from the comfortably unsound practices of today to a world of 21st century cognitive engineering.
This roadmap is a sketch, and necessarily will change as we progress. Realistically, the real world is also far less linear than this simplified map might make it seem. We have already done a fair amount of work on Vertical Scaling (Phase 4) and Cognitive Emulation (Phase 5), and lots of work of Phase 1 and Phase 2 happens in parallel.
Phase 1: Foundational Infrastructure
We have been doing research on cognitive algorithms for almost two years now, and so, so many problems in AI development start way, way before you even touch a neural network.
What we have found again and again is that more often than not, one of the biggest pain points of our work was for researchers to just have a nice interface to quickly write their own AI scaffolding without dying to Python research-code hell. Over and over again, we were slowed down more by poor devops than we were by research ideas or execution.
And especially for non-research code, whenever we wanted to build a useful AI app, like a writing assistant, or an internal Perplexity-like AI search engine, we would get stuck in moving from experiment to production. We could write our own cognitive software and impressive heuristics, but then inevitably would end up spending inordinate amounts of time managing database connections, sessions, authentication and other odds and ends that were just distractions and hindrances from actually developing and deploying cool stuff.
So the first step in building a 21st century cognitive software stack is solving these 20th century devops headaches for good. All the most clever cognitive code is useless if the underlying infrastructure doesn’t work, or is hell to use.
Our new platform, tactics.dev, takes solving this problem to the extreme. With Tactics, we take care of the backend, combining some of the best ideas of services like firebase and cloud functions, with first-class AI support.
Using Tactics, anyone can create a tactic with a few clicks, and as little as a single line of code (here to ask an LLM to give us a fluffy animal):
selected_animal = $do(“give me a random fluffy mammal”)
…that’s all that’s needed to have your API up and running! You get parallelism, auto scaling, LLM ops, devops, secure authentication and more straight out of the box, no setup needed!
This makes iterating on AI-first workflows and deploying them to production easier than ever, no slowing down or getting caught up in managing fiddly backends, just focus on what matters.
Tactics already has many useful features such as:
First class LLM support. Switch between model providers and manage your API keys with ease.
Every tactic is an API. The moment you have written your tactic, you have a REST endpoint you can hit.
No async/await pollution. Just make llm calls and put the results into variables. It just works.
Just assume the database is always there. No need to open a connection, no dangling closes.
Sessions and authentication are directly integrated, no setup required.
Tactics.dev is rapidly developing, and we want your feedback for making it better! Deploying an AI app should be a breeze, so you can focus on building the hard parts of your application, and we need your input to help make the experience as good as it can possibly be.
Try tactics.dev today!
Phase 2: Cognitive Language Design and Computational Control
Sometimes when thinking about the massive potential of AI, people talk about “aligning” AI systems to humanity’s wishes. This is often seen as an impossibly esoteric field of study that resembles abstract philosophy more than any actual form of engineering.
We disagree with this, and think there is already a rich, powerful field of study concerned with exactly the problem of how to express a human’s wishes to a computer efficiently in such a way that they get what they wanted: Programming language design.
When people talk about coding in the AI era, they imagine coding with the exact same programming languages and paradigms from 20 years ago, just with a little AI assistant talking to you and regurgitating javascript boilerplate for you.
This is obviously ridiculous and dramatically lacking in imagination and ambition. We need to go back to the drawing board. What does programming language design for the cognitive software era look like? What are the new abstractions? The new primitives? What if you design your entire language around deep integration with, and management of, complex cognitive systems, rather than treating them as a clunky API pasted on top of your existing software semantics?
We have developed our own programming language, CTAC (Cognitive TACtics), with which we are doing exactly this kind of exploration. It’s somewhere halfway between a traditional programming language and a prompting language, allowing for easy and strongly integrated access to the LLM backend. Language design is very hard without sloppifying the language (as can be seen with ~all of the most widely used languages today), so we are still iterating.
But why a programming language? Why not just a library or framework in a more popular language? There are a number of reasons.
First, you always will inherit the mountain of slop complexity that comes with any existing language and its package and tooling ecosystem. And lets face it, one glance at any programming forum is enough to tell how people feel about the quality of the languages and ecosystem of the most popular languages (hint: Not Good). These languages and their tooling simply come with decades of organic growth and accumulated technical debt, which makes supporting and building on them hell.
Second is that we fundamentally want to do things that are hard or impossible to do with current languages in “user land” alone. A good inspiration for our thinking is Ltac, the “tactics language” of the extremely powerful theorem prover Coq (You may notice an etymological inspiration for our own tools).
Ltac is a stateful language for managing the proof context. It lets you manage your current assumptions and conclusions that are still left to prove.
There are many control flow options and heuristics in Ltac that are not part of common programming languages. An example is the keyword “try”, which tries a tactic, and if it fails, reverts the entire proof state back to what it was before, and tries again. Doing this as the user of another language would require having access to all of the state of the whole program, which can be done, but is extremely painful. In Ltac, it’s just a single keyword.
Similarly, there are many high-level heuristics and control flows that you would want to use when building cognitive software, and we want to integrate great primitives to do so into the language itself.
There are many other patterns of control flow like this, such as:
Semantically aggregate the result of applying a tactic to a folder/20 websites/etc
Pick the tactic that is most relevant given a context and guardrails
Look at the recent execution trace, and see if things went wrong and execution should be interrupted until a human takes a look
We have often wanted to implement features like these cleanly. It can be done in other languages, but it is often extremely ugly. We have often had to struggle with lots of boilerplate from badly integrated libraries, or suffered from programming languages’ lack of strong control flow primitives. If you wanted to implement proper advanced control flow in a library/user-land correctly, you’d need languages with features like typed Effects and well-typed Metaprogramming, and for some reason in the year of our lord 2024, most languages still have neither.
But, we don’t need typed Effects or well-typed Metaprogramming to implement such things in CTAC, because we control the language! So when we want to implement new control flow primitives, we can just directly modify the interpreter! (Though we may still be coming back to implementing a proper typed Effect System…)
And third, there are new abstractions and primitives to be discovered and implemented for the cognitive programming era! We are working on finding these right abstractions, and our control of the language allows us to iterate on and smoothly integrate these new primitives.
What could new, cognitive primitives look like? We could natively track uncertainty throughout program execution, and bound the context of the cognitive coprocessers precisely and painlessly. What if we had keywords such as “reflect”, that allows the cognitive system to look at its own recent execution trace and write down its thoughts about it, or “reify”, going through a trace and distilling it into a tactic, all directly and deeply integrated into the language?
CTAC is still far, far from feature complete, and should be seen as an early proof of concept. Phase 2 is going from where we are now to a true 21st century cognitive programming language. Having full control over the language will allow us to implement features and build tools that just aren’t possible otherwise, or that would be crushed under the weight of inherited technical debt from other, older languages.
If you want to try out CTAC, you can do so on Tactics.dev, here!
Phase 3: Horizontal Scaling: Scaling Without Sprawling
Now that we can write, execute and deploy individual cognitive programs effectively, how do we scale? How do we get from small chunks of cognition to large, powerful systems that do what we want and cover the scope of what we care about?
There are two kinds of scaling: Horizontal and Vertical. Horizontal Scaling is about breadth, increasing the scope of different tasks of similar maximum complexity and putting these parts together into a larger system while keeping it coherent and manageable. Vertical Scaling is about depth, increasing the depth and maximum complexity of individual parts of the system. Horizontal is about solving more tasks, Vertical is about solving harder tasks.
We start with Horizontal Scaling. Adding more and more simple features, intuitively one might think, should not result in an overall complex system, but this is almost always what happens. This is the problem of Horizontal Scaling. How do you build and maintain many different cognitive components? How do you make sure they remain coherent and compatible as the scope and size of the project grows? How do you maintain oversight of the whole system and its capabilities, and confidence in its safety?
As a motivating example, let's look at one of our early inspirations for our approach to cognitive engineering: Voyager.
Voyager is an amazing paper, I really recommend you read it and check out their videos if you haven’t seen it before. The basic goal is to get GPT4 to play Minecraft. To do this, they build a pipeline of prompts that generate snippets of JS code (“skills”) that interact with an API to play Minecraft to solve various tasks. Crucially, as the tasks become harder, the new “skills” can refer to and reuse previous “skills.” The neural network never directly interacts with the environment, only through these little “shards” of code. Lets call this type of system a “Crystalline Learning System” (CLS), as it "crystallizes" its learning into discrete shards of code, rather than encoding everything in fuzzy neural weights.
Lets consider a generalized CLS, that interfaces directly with a keyboard and mouse on an open ended computer rather than just with Minecraft. By default, this is quite unsafe, there is no bound on what such a system might learn or do. But notice there is actually little that is needed to make this bounded and manageable: Its artifacts are just regular JS programs that are quite legible to people, and we can apply all kinds of complexity and legibility measures to them (both of the traditional and AI variety).
This is an approach to Horizontal Scaling: Without needing to make the base model a more and more powerful blackbox, we can extend the capabilities of the system in a way that humans can understand and control. You could even have the humans write these cognitive shards, or tactics, directly!
The first and most important part of any development and debugging loop is the human in the loop. A developing codebase is not a static thing, but an interactive system with its human developers, and giving the developers the tools and affordances to interact with and intervene on the system when needed is crucial.
There are 3 possible times for human in the loop:
Static analysis: Review the code before it is run.
Runtime analysis: Monitor the code as it runs and pause its execution when needed.
Trace analysis: Look at the trace of execution after the fact and figure out what happened.
All of these points of human-machine interaction can be turbo-charged with strong principles, good tooling and, if done right, AI to automate what has been crystallized from experts.
The key to doing Horizontal Scaling is to get this right. If you do this kind of stuff, especially integrating AI in the devloop, naively, you just get slop. If you use tactics that just generate super sloppy new tactics that don’t compose well, that do not preserve invariants and implicit properties, everything goes to complexity hell really quickly.
You can see this effect in action with Voyager: Taking a look at some of the skills Voyager developed during a run, it has some very sensible skills such as “craftChest.js” and “mineCoalOre.js”, then ends up with badly abstracted slop like “catchFiveFishSafely.js”, “mineCopperOreWithStonePickaxe.js” and “mineFiveCoalOresV2.js”
We need to apply strong safety engineering and software architecture principles to do this in a way that scales horizontally cleanly and properly, rather than ensloppifying everything. This is the key problem that Phase 3 must solve.
And there is a lot here to be done! Better type systems, time-travelling and multiversal debuggers, prompt tracing, neural debuggers (programs that analyze neural networks, attention patterns, etc, directly to guide debugging of prompts. We have developed quite a bit of this in house, but they’re not quite yet ready for wider release), and, eventually, properly constrained and reliable AI reviews and tests.
But we must go further than this. Bring back complexity measures like cyclomatic complexity, and improve on them with all the knowledge we’ve accumulated since they were introduced! Have you heard of FRAP? It’s a book from the future about writing correct software that somehow ended up in the early 21st century instead of the 22nd century, where it belongs. We should apply it to building cognitive software if we want to scale and manage our complexity!
Phase 4: Vertical Scaling: Deliberate Teaching and Cognitive Provenance
Proper Horizontal Scaling is already insanely powerful, and allows us to cover a vast and expanding scope of relevant tasks, especially when fueled by the powerful cognitive engines (LLMs) already in existence today.
But sometimes, you need the underlying cognitive engine to exhibit new behaviors that shards/tactics are just not a good medium for, such as:
Automations that should be quick and not need to go through the equivalent of 17 post-its.
Tasks involving “vibes” or styles that would be too painful not only to put into code, but also to maintain and edit in a coherent way.
Facts that should be baked into the model for when it performs other tasks.
Right now, our solutions to these problems are terrible. Whether it is pretraining or finetuning, we just feed the model piles of data and hope that the increase in measurable evals translates into better performance on the tasks we care about. This goes against our philosophy, which is to craft and understand what is happening when we add capabilities to our system.
What we would want is a training procedure that lets us understand what the model does and does not know at each step. What might that look like?
One would need some kind of “deliberate teaching” procedure by which one can selectively add pieces of knowledge, check if it was integrated into the model, and how it was integrated. You would want to be able to know how the new knowledge generalized and interacted with other patterns and knowledge, and revert back in case something happened that was not intended.
Such a procedure is the fundamental cognitive building block for constructing vertically scalable AI systems in a safe and controllable way. But we still have the problem that if we build off of already pretrained models, we can’t know everything that is already in them, and reverse engineering seems hopeless.
Taking things a step further, the speculative ultimate result of applying this constructivist spirit to pretraining would be what we call “Empty Language Models” (ELMs), models that are trained first exclusively on patterns but not on facts.
Once you have a base model that is “empty”, you can then one by one add the relevant facts and information you want to use in your application context. And throughout this procedure, you monitor and control the learning and generalization process, such that you know not just what information went into your model (Provenance), but also what generalizations it learned from that data (Cognitive Provenance).
Through ELMs, we can even speculate of creating a kind of “Cognitive Fourier Analysis”, where we can separate the “low frequency patterns” of generalization from the “high frequency patterns” of fact recalling, and then use this information in our debugging and software development loops.
This is the philosopher’s stone of how to turn AI into software engineering. The ability to add and subtract information and monitor the patterns that your cognitive system has access to should make possible not just Cognitive Provenance, but also cognitive unit tests, formal guarantees, and more.
In practice, sadly, developing a true ELM is currently too expensive for us to pursue (but if you want to fund us to do that, lmk). So instead, in our internal research, we focus on finetuning over pretraining. Our goal is to be able to teach a model a set of facts/constraints/instructions and be able to predict how it will generalize from them, and ensure it doesn’t learn unwanted facts (such as learning human psychology from programmer comments, or general hallucinations).
This research is highly speculative at this time, but we have made significant progress on this agenda, and think we know how to get all the way. This is not likely to be in public facing products in the short term, but if you are interested in this, get in touch!
Phase 5: Cognitive Emulation (CoEm)
There is a lot of software architecture and ML research to be done, many systems to build, problems to solve, and this will take time. But it’s worth speculating a bit further.
Ultimately: Where does this all lead?
Right now, we are focusing on short, self-contained programs that can be integrated in larger environments. But how do we scale all the way? How can we build humane and legible cognitive edifices that scale gracefully both in scope and complexity all the way to solving our real, human problems?
Our claim is that the way to get there is to write cognitive programs that emulate human cognition. “Cognitive Emulation”, or “CoEm”.
The way humans solve problems, our type of cognition, is a very specific kind of cognition, and it is different from just telling an AI to solve a problem by whatever means it wants. AI cognition is very different from, and inscrutable to, humans!
In mathematics, there is a notion between researchers of “proof techniques”, tricks and techniques to aid in solving tricky mathematical proofs and problems. Curiously, there is no article on proof techniques on Wikipedia, because these techniques mostly spread via oral transmission.
But some of these proof techniques have been studied in such great detail that they do feature in their own first-class Wikipedia articles, such as forcing, Ehrenfeucht–Fraïssé games or defining greedoids to prove optimality of greedy algorithms. A major milestone of the CoEm agenda would be to systematically distill intuitions such as these to the point they can be reused in cognitive software at scale.
Teaching is an interactive process, there is a back and forth. Books are not very good at this, their linearity can never adapt to the combinatorially explosive nature of possible interactions and possible readers. Iteratively building an interactive teacher in a humane way, that doesn’t hallucinate, where both the students and the teachers master the topics together as they interact, is at the core of the CoEm aesthetic.
The more varied people you can teach something to, the more deeply, you, as a teacher, understand the concept.
With DL, you just feed more data, lol. In a CoEm world, the experts building the systems themselves would be enriched over the course of their many interactions with the systems they build.
And emulating human cognition gives us extremely economically valuable systems (the current economy after all is built entirely on this type of cognition!) that our institutions are already adapted to, and that we can understand and audit and make safe.
Software is a huge topic, involving many different types of thinking, and has amongst the shortest timespans from “idea” to “real thing that people can use”. This makes it a very special field, there are few others where a kid with a laptop can realistically build and deploy something novel that can improve the lives of millions. This makes it so much the sadder that DL has been used to enshittify, rather than enliven, it. With CoEm, we should get better software than the ones we’d write without AI, not worse.
Building well architected CoEm systems would allow us to get the wonderful economic benefits of AI software, while maintaining systems that can be understood and integrated into already existing human institutions cleanly.
We have a lot to say about this, what human cognition is, how to achieve it, etc, but that will have to wait for another day.
Conclusion: A Future Worth Building
This all assumes of course that we make the sensible choice to not go straight for ASI, the same way we eschew building other catastrophic technologies. A Narrow Path lays out what that might look like from a policy standpoint.
If we do, we firmly believe that one of the greatest bottlenecks to getting to a future of incredible economic, scientific and even just entertainment abundance is humanity’s collective poor practices in designing, building and maintaining software. If we carry these practices forward into AI, the outcome will be even worse.
This makes us optimistic rather than pessimistic. Not because humanity has a particularly good track record of building complex software well (just look at any software vulnerability database and weep), but because the same solutions that will make AI systems beneficial will also make them safer.
We have decades of hard-won knowledge about building and maintaining complex software, and concrete examples of success in other critical domains - from flight control systems to nuclear reactor design. If we applied the levels of rigor that we apply to flight control systems or nuclear reactor design to AI systems (or hell, even just got Adam Chlipala to do it)…yeah, that could really work!
This doesn’t solve the problems of misuse or negligence. You can still misuse software, or write bad software on purpose. But what we need is to apply the rigor of engineering to AI development, develop and standardize best practices for cognitive software engineering, and make it not just possible but straightforward to write good AI software.
The path to beneficial AI isn't mysterious - it's methodical.
This is where you come in. Whether you're a developer looking to build better AI applications, a researcher interested in cognitive software architecture, a company wanting to deploy AI systems responsibly and reliably, or someone concerned about the future of AI development, we invite you to join us in building this future.
The journey starts with practical steps. Try our tools at tactics.dev and share your experiences. Engage with our research and development principles. Help us develop and refine best practices for the field. Share your challenges and insights in building cognitive software.
The future of AI doesn't have to be mysterious black boxes or uncontrollable systems. We can build a future where cognitive software is understandable, reliable, and truly beneficial to humanity.
Ready to start? Sign up for our alpha test, follow our progress on X, or reach out to us directly. Together, we can transform AI from black box to building block.
The future of AI isn't predetermined - it's engineered. Let's build it right.